
티스토리 뷰
발생일: 2020.07.25
키워드: 엘라스틱서치, elastic search
문제:
엘라스틱서치로 검색을 구현하려고 한다.
시작하기 문서를 찾아서 봤는데, 너무 이해하기 쉽게 잘 설명해준다.
아래는 노트해둔 것.
해결책:
엘라스틱 서비스
- Kibana 시각화 도구
- Elastic Search 검색 도구
- Beats, Logstash 수집 도구
- 이거 합해서 엘라스틱 스택
기타 기능
- 엘라스틱 사이트 서치: 사이트 URL 넣으면 색인 모두 만들어줌. 자동완성과 검색 제공하는 자바스크립트 모듈만 넣으면 된다고 함
- 엘라스틱서치 사이트에서 support matrix 라고 검색하면 지원환경 알 수 있음
- 엘라스틱서치 7버전부터 JDK를 같이 포함하고 있어서 자바 설치 안해도 됨
디렉토리 설명
- 다운로드: https://www.elastic.co/kr/downloads/elasticsearch (MacOS 용 다운로드 받음)
- config 내 elasticsearch.yml (야믈 파일)이 가장 중요한 설정
elasticsearch.yml
- network.host: 파일에 호스트를 설정해야 프로덕션으로 가능함
- http.port: 기본적으로 REST API로 통신함. 기본 포트는 9200
용어
- 도큐먼트: 단일 데이터
- 인덱스: 도큐먼트 집합. 저장 단위인 인덱스는 indicies 라고 표현하기도 함
- 색인: 저장 행위
- 샤드: 인덱스는 기본적으로 샤드(shard)라는 단위로 분리되고, 각 노드에 분산되어 저장됨
실행 및 테스트
- 실행할 땐 ` bin/elasticsearch` 으로 하면 됨. 노드 이름으로 실행됨
- 9300번 포트로 다른 서비스와 통신, 9200번 포트로 클라이언트와 통신
- $ curl localhost:9200
데모
- https://github.com/kimjmin/elastic-demo/tree/master/demos/get-started
- 색인 생성 데모
- https://github.com/kimjmin/elastic-demo/blob/master/demos/get-started/elasticsearch-7x.md
- PUT/GET
- 구조는 localhost:9200/[인덱스명]/_doc/[도규먼트ID]
- 7.0부터는 타입 개념이 없어져서 _doc 으로 붙으면 됨
- PUT으로 REST API로 넣을 수 있음
- 넣고 나서는 같은 이름으로 GET으로 가져올 수 있음
- 엘라스틱서치는 한 URL이 한 도큐먼트를 가리키고 있음 (같은 URL로 넣으면 덮어써짐)
- POST
- POST는 도큐먼트 ID를 자동으로 생성함
- DELETE
- DELETE 로 삭제하면 되고, 도큐먼트 또는 인덱스 단위로 모두 삭제할 수 있음
키바나 데모
- config/kinana.yml 이 주요 설정 파일
- 로컬 호스트가 아니라 엘라스틱서치와 다른 서버로 실행하고 싶다면, elastic_server 설정 변경하면 됨
- bin/kinana 로 실행. 5601번 포트가 기본 포트
- 메뉴 > Dev Tools 에 가면 여러 가지 테스트해볼 수 있음
Bulk API
- 대용량인 경우, 기본가 bulk는 10배 이상 차이남
- POST /_bulk
- index, create, update, delete 동작 가능
- delete를 제외하고, 명령문과 데이터문을 한 줄씩 순서대로 입력
- 또한, 명령문과 데이터문은 반드시 한 줄 안에 입력되어 있어야 함 (줄바꿈을 허용하지 않음)
- 모든 명령이 동일 인덱스에서 수행되는 경우엔, 인덱스명/_bulk API 로 호출할 수 있음
- 엘라스틱서치는 커밋이나 롤백 등 트랜잭션 개념이 없음
- _bulk 작업 중 연결이 끊기거나 시스템 다운 등으로 동작이 중단된 경우, 어디서 중단됐는지 확인 불가함
- 이럴 땐 인덱스를 삭제하고 처음부터 다시 하는 것이 안전함
Search API
- GET 인덱스/_search 로 요청
- q 파라미터로 검색어를 전달할 수 있음. /_search?q=value
- q="a and b" 나, q=field:value 같은 패턴으로 검색 가능
- 데이터 본문으로 검색: query 옵션으로 검색 조건을 씀
- match: 필드 + 검색어로 설정함
- 검색어는 term 이라고 함. 공백으로 구분하면 기본적으로 OR 조건. 예) dog fox
- AND를 하려면 "operator": "and" 조건을 주면 됨
- match_all: 인덱스의 모든 것을 가져옴
- match_phrase: 검색어를 하나의 구문으로 검색함
- slop: 1 옵션을 주면, '스키 장갑' 같은 검색 시, '스키 벙어리 장갑', '스키 보드 장갑'도 검색 가능
- 엘라스틱서치의 Query 구문은 모두 JSON 형식으로 입력함
- 베이직 이상 라이렌스에서는 표준 SQL문을 사용해 검색 가능하지만, 기능에 제한이 있으므로 JSON 형식을 쓸 것을 권장함
멀티테넌시 (Multitenancy)
- 엘라스틱서치는 여러 인덱스를 한꺼번에 묶어 검색할 수 있는 멀티테넌시를 지원
- logs-2020, logs-2019 같은 인덱스가 있다면, logs-*/_search 명령으로 한꺼번에 검색 가능
- 인덱스는 쉼표(,)나 와일드카드(*)로 묶을 수 있음
- GET logs-2020,logs-2019/_search
- GET logs-*/_search
복합 쿼리
- 복합 쿼리. query에서 "bool" 옵션으로 서브쿼리를 조합할 수 있음
- must: 쿼리가 참인 도큐먼트들을 검색
- must_not: 쿼리가 거짓인 도큐먼트들을 검색
- should: 검색 결과 중 이 쿼리에 해당하는 도큐먼트의 점수를 높임
- filter: 쿼리가 참인 도큐먼트를 검색하지만 스코어를 계산하지 않음. must 보다 검색 속도가 빠르고 캐싱됨.
- 각 항목에 서브쿼리를 배열로 전달할 수 있음
- 예를 들어, 특정 아파트의 리뷰만 검색하려고 한다면,
- must 에는 키워드를,
- filter 에 아파트 아이디를 넣는 방법 (스코어에 영향을 주지 않고 더 빠르니까)
- should 는 match_phrase 와 함께 쓰면 유용함
- 예를 들면, 검색 결과 중 입력한 검색어 전체 문장이 정확히 일치하는 결과를 맨 상위에 위치시킬 수 있음
- 나머지 결과는 누락하지 않은 채 볼 수 있음
- 복합쿼리 안의 배열은 AND 조건임
- 예: must: [ { queryA }, { queryB } ] -> queryA AND queryB 를 의미
- OR는 검색어를 공백으로 구분해 적용할 수 있음
Relevancy (정확도)
- https://esbook.kimjmin.net/05-search/5.3-relevancy
- 검색 결과의 스코어는 BM25 알고리즘을 사용함
- BM25 계산식은 TF, IDF, Field Length를 사용함
- TF: Term Frequency. 도큐먼트 내에 검색된 텀(Term)의 개수가 많을수록 점수가 높음. BM25에서는 최대 25까지 증가함
- IDF: Inverse Document Frequency. 검색한 텀을 포함하고 있는 전체 도큐먼트의 개수가 많을수록, 해당 텀의 점수가 감소함
- Field Length: 텀을 포함하고 있는 필드의 길이가 짧을수록 점수가 높음.
Exact value query (정확값 쿼리)
- 풀 텍스트는 정확도를 측정해서 스코어로 정렬함
- exact value 쿼리는 참/거짓 여부만 판별해서 결과를 가져옴
- term, range 같은 쿼리가 이 대상임
- 문자열 데이터는 keyword 형식으로 저장하면 정확값 검색이 가능함
- 예: message 필드가 있다면, message.keyword 필드를 검색 대상으로 잡으면 됨
- 스코어를 계산하지 않기 때문에 보통 bool 쿼리의 filter 내부에서 사용함
- filter 안에 넣은 검색 조건들은 스코어를 계산하지 않지만 캐싱이 되기 때문에 쿼리가 더 가볍고 빠르게 실행됨
- 스코어 계산이 필요하지 않은 쿼리들은 모두 filter 안에 넣어서 실행하는 것이 좋음
Range 쿼리
- range 쿼리
- gte (Greater-than or equal to): 이상 (같거나 큼)
- gt (Greater-than): 초과 (큼)
- lte (Less-than or equal to): 이하 (같거나 작음)
- lt (Less-than): 미만 (작음)
- format 속성을 정의할 수 있음
- y, M, d, H, m, s 로 입력 가능
- 예: "format": "yyyy-MM-dd"
- 예: "format": "yyyy-MM-dd||yyyy" (|| 로 OR 패턴을 넣을 수 있음)
- 날짜인 경우 키워드로 조회할 수 있음
- 예: "gt": "now-2y": 오늘부터 2년 전 이후보다 큰 값
- 예: "gt": "2020-01-01||+6M" -> 2020년 1월 1일에 6개월을 더한 값보다 큰 것
- range 또한 스코어가 없어서 filter 조건으로 넣는 것이 좋음
- range 에 따른 스코어를 주고 싶을 땐 function_score 쿼리를 사용해서 조정이 가능함
텍스트 분석
- 엘라스틱서치에 색인될 때 검색에 필요한 형태로 분리됨
- API _analyze 로 애널라이저(analizer) 정보를 볼 수 있음
- 애널라이즈 만들기 전에 미리 분석해보면 좋을 듯
- 애널라이저(analizer)는 토크나이저(tokenizer)와 여러 개의 필터(filter)로 구성됨
- Tokenizer 을 통해 문장을 검색어 텀(term)으로 쪼갬
- Filter(토큰필터) 를 통해 쪼개진 텀들을 가공
- 필터 예: lowercase, unqiue, stop(불용어 제거)
- T: standard, F: lowercase -> 스탠다드 토크나이저 + lowercase 필터
역인덱스 (Invereted Index)
- https://esbook.kimjmin.net/06-text-analysis
- 데이터를 저장할 때 검색 가능한 term (검색어 토큰) 으로 색인을 생성함
- 예: doc1 = 'lazy dog' -> lazy: doc1, dog: dog1 과 같이
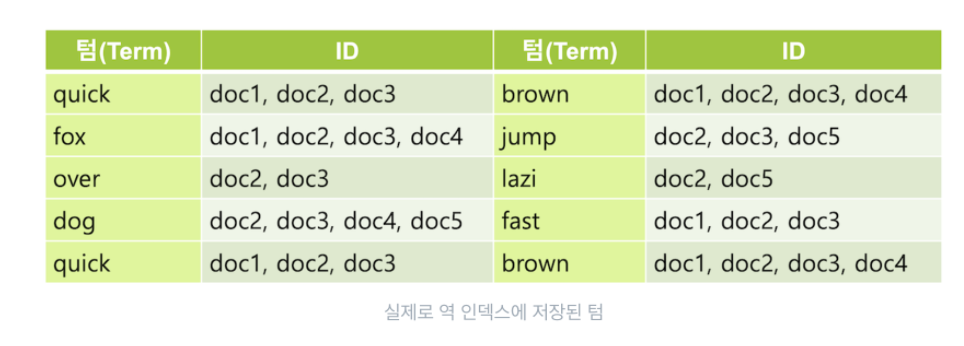
- 엘라스틱서치에 저장되는 도큐먼트의 모든 문자열(text) 필드의 역 인덱스를 생성함
- 애널라이저(Analyzer)
- 텍스트 분석 (Text Analysis) 과정: 문자열 필드가 저장될 때, 데이터에서 검색어 토큰을 추출하는 여러 과정
- 텍스트 분석을 처리하는 기능 = 애널라이저
- 애널라이저
- 0~3개의 캐릭터 필터, 1개의 토크나이저, 0~n개의 토큰 필터로 이루어짐

- 캐릭터 필터(Character Filter)
- 전체 문장에서 특정 문자를 대치하거나 제거
- 예: 특수문자 제거, 특정 키워드 치환
- 7.0 기준으로 strip, mapping, pattern replace 3개가 있음
- char_filter 항목에 배열로 입력 가능
- 토크나이저(Tokenizer)
- 문장에 속한 단어들을 텀 단위로 하나씩 분리
- 토크나이저는 반드시 1개만 적용이 가능함
- 예: whitespace 토크나이저: 공백을 기준으로 텀 들을 분리
- 토큰 필터(Token Filter)
- 분리된 텀을 가공
- 예: lowercase 토큰 필터: Lazy, lazy 를 같은 텀으로 병합
- 예: stop 토큰 필터: 검색 가치가 없는 단어를 불용어(stopword)로 간주해 토큰에서 제외
- 예: snowball 토큰 필터: 문법상 변형된 단어를 기본 형태로 변환, jumps -> jump, jumping -> jump
- 예: synonym 토큰 필터: 동의어를 텀으로 추가. quick -> fast 를, aws -> amazon 을 추가
- 애널라이저를 정의해서 바로 할당할 수 있음
- 검색 시 검색어도 애널라이저를 거쳐 term 으로 변형돼, 색인된 값을 검색함
- 한국어 형태소 분석기를 쓴다면, '수영장' -> '수영' + '장'으로 분리되어 검색되는 것임
- 검색할 때 애널라이저를 적용하지 않으려면 "term" 쿼리를 사용하면 됨
- 예: "query": { "term": { "message": "jump" } }
사용자 정의 애널라이저
- https://esbook.kimjmin.net/06-text-analysis/6.3-analyzer-1/6.4-custom-analyzer
- 인덱스에 적용할 땐 사용자 정의 애널라이저를 만들어 적용하는 것이 편함
- PUT 인덱스명/_analyze 로 추가
- settings 프로퍼티로 커스텀 애널라이저와 커스텀 필터를 먼저 설정하고,
- 이 값을 데이터에 적용할 땐, mappings 프로퍼티로 대상 필드에 넣어주면 됨
- 도큐먼트 토큰은 _termvectors API로 확인 가능
- GET 인덱스/_termvectors/[id]?fields=foo,bar
한글 형태소 분석기
- 별도 플러그인을 설치해야 함
- bin/elasticsearch-plugin install analysis-nori
- T: nori_tokenizer 로 분석해보면 다른 결과를 볼 수 있음
- 한국어 사전 기반으로 분석됨
사용자 정의 애널라이저
- 인덱스는 도큐먼트의 모음
- settings 와 mapping 로 구분됨
- settings: 애널라이저, 샤드개수, 리프레시 기준 등
- mapping: 필드의 명세, 텍스트라면 어떤 애널라이저를 쓸 것인지 등
- 한 번 만든 인덱스의 설정 대부분은 변경 불가능함
- 리프레시 타임이나 리플리카 샤드 개수 등은 수정할 수 있으나, 대부분 변경 불가
- 토큰 필터: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html
집계
- 검색이 아니라 집계
- metrics 와 bucket이 있음
- metrics: min, max, sum, avg 등의 계산
- bucket: 특정 기준으로 도큐먼트들을 그룹화
메트릭스 집계
- 검색할 땐 query 대신 "aggs" 속성을 줌
- "size": 0 을 주지 않으면, hits 결과가 함께 나오니 집계만 할 거면 적용하는 게 좋음
- 집계를 query 와 같이 하면, 결과의 합계만 집계함
버킷 집계
- 날짜별 히스토그램 (date_histogram)
- 예: date_histogram으로 date 필드를 1개월 간격으로 구분하는 bucket aggregation
- 기본적으로 문서 개수를 리턴(doc_count)
- keyword 타입 = 분석하지 않고 통으로 저장함
- 메트릭스 집계를 같이 사용할 수 있음
위치 정보
- geo_point : { "lat": 41.12, "lon": -71.34 } 같은 형식으로 입력
- geo_bounding_box : 두 점을 기준으로 하는 네모 안에 있는 도큐먼트들을 가져옴
- geo_distance : 한 점을 기준으로 반경 안에 있는 도큐먼트들을 가져옴
노드: 엘라스틱서치 인스턴스
- https://esbook.kimjmin.net/03-cluster/3.3-master-and-data-nodes
- 노드에 여러 인덱스를 생성할 수 있음
- 한 노드는 9200번 포트로 클라이언트와 통신, 9300번 포트로 다른 노드와 통신
- 여러 노드를 하나의 클러스터로 묶을 수 있음
- 클러스터 > 노드 > 샤드
- 노드 하나는 동시에 여러 역할을 할 수 있음
- master: 마스터 후보
- data: 데이터 저장
- ingest: 데이터 색인 전처리 작업 수행
- ml: 머신러닝 작업 수행
- 아무 것도 설정 안하면 클라이언트와 통신만 하는 역할
- 마스터 노드와 데이터 노드를 분리하면,
- 마스터 노드는 클러스터 관리만 하면 되고, 데이터노드는 데이터 처리에 집중할 수 있어 효율적임
- 마스터 전용 노드를 Dedicated master node 라고 함
- Split Brain 이슈
- 마스터 노드가 1개면 마스터 노드가 유실되었을 때 클러스터 전체가 작동하지 않을 위험이 있음
- 짝수 개라면 네트워크가 끊겼을 때 정합성 이슈가 생길 수 있음
- 마스터 노드는 3개 이상의 홀수 개를 놓은 것을 권장, 마스터 후보 노드가 최소 2개 이상 존재하도록 하는 것이 좋음
샤드
- 샤드: 인덱스는 기본적으로 샤드(shard)라는 단위로 분리되고, 각 노드에 분산되어 저장됨
- 클러스터에 노드를 추가하면, 샤드들이 각 노드들로 분산됨
- 기본적으로 1개의 복제본을 생성함
- 처음 생성된 샤드를 프라이머리 샤드(Primary Shard), 복제본은 리플리카(Replica)라고 함

- 최소 3개의 노드로 구성할 것을 권장함
- 샤드는 반드시 서로 다른 노드에 저장되며, 노드가 유실되면 남아있던 샤드가 프라이머리로 승격되고 다른 노드로 복제본을 생성함
- https://esbook.kimjmin.net/03-cluster/3.2-index-and-shards
- 샤드는 인덱스 단위로 생성할 수 있고, 샤드의 개수는 인덱스를 처음 생성할 때 지정할 수 있음
- 프라이머리 샤드의 개수는 인덱스 재색인 전에는 변경할 수 없음
- number_of_shards: 프라이머리 샤드 개수
- number_of_replicas: 리플리카 개수
- 예: 프라이머리 5개, 리플리카 1개 = 5 * (1 + 1) = 총 10개의 샤드
- 유실되지 않으려면, 노드 개수 * 2 * 2 정도의 샤드는 있어야 할 듯?
인덱스 설정
- 인덱스는 두 개의 정보를 가지고 있음. settings & mappings
- https://esbook.kimjmin.net/07-settings-and-mappings/7.1-settings
- settings
- 프라이머리 샤드 수는 인덱스를 생성할 때 한 번 설정하면 바꾸기 어려움
- 7.x부터 기본 샤드 수는 1개, 6버전 이하는 5개였다고 함
- mappings
- properties
- 생략하면 값을 보고 직접 설정함
- 매핑 필드를 한 번 설정하면 변경할 수 없음 (인덱스를 새로 만들어야 함)
- type
- 타입
- 문자열
- text
- https://esbook.kimjmin.net/07-settings-and-mappings/7.2-mappings/7.2.1
- 문자열 역인덱스를 생성함
- analizer, search_analizer를 설정할 수 있음
- keyword:
- 입력된 문자열을 하나의 토큰으로 저장
- 집계나 정렬할 때 사용하는 경우 자주 사용함
- normalizer 적용이 가능 (노멀라이저는 캐릭터 필터와 토큰 필터만 적용 가능)
- 숫자
- long, integer, short, byte, double, float, hal_float, scaled_float
- coerce 옵션이 있음. 자동으로 형변환 됨
- ignore_malformed 를 true 로 설정하면, 값이 오류가 있어도 저장함. 소스에는 저장이 되나 검색 대상에서는 제외됨 (기본값 false)
- date
- ISO8601 포맷면 됨
- format 으로 별도 포맷을 설정할 수 있음
- epoch_mills, epoch_second 도 사용 가능
- 예: "format": "yyyy-MM-dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
- boolean
- true 또는 문자열 "true"
- object
- 객체 형태로 넣을 수 있음
- 다만, 검색할 때 query 내에 "nested" 쿼리를 사용해야 함
- geo
- 위도(latitude)와 경도(logitude)를 넣음
- https://esbook.kimjmin.net/07-settings-and-mappings/7.2-mappings/7.2.6-geo
- geo_point와 geo_shape 형식으로 저장 및 검색 가능
- geo_shape: point, multipoint, linestring, mutilinearstring, polygon, mutlipolygon, envelope (직사각형 영역)
- 폴리곤과 멀티폴리곤의 한 폴리곤의 시작점과 끝점은 동일해야 함
- 포인트 쿼리
- geo_bounding_box: 박스 내 좌표 검색
- geo_distance: 특정 포인트부터 원형으로 영역 내 좌표 검색
- geo_shape 쿼리
- relation 으로 검색
- intersects: 기본값^ 일부만 겹치면 됨
- disjoint: 겹치지 않는 도큐먼트
- within: 완전이 포함되어 있는 도큐먼트
- 이 외에 geo_polygon으로 검색할 수도 있음
- 참고로, 전처리된 데이터가 아니면 항상 _source 의 값은 변경되지 않음
참고:
- 시작하기 영상: https://www.elastic.co/kr/webinars/getting-started-elasticsearch
- 가이드북: https://esbook.kimjmin.net/01-overview/1.1-elastic-stack